191 Million URLs. 4.2 Million Indexed. One Exchange's Invisible Revenue Crisis
191 million URLs submitted. 4.2 million indexed. A top-10 crypto exchange was losing millions in organic revenue from an indexation failure no one was watching. Here's exactly how we diagnosed it.


We got a call from the CMO of a top-10 global crypto exchange last quarter. The conversation started the way these calls usually start: traffic was plateauing. Competitors were gaining ground in organic search. The in-house SEO team had tried everything they could think of. New content, new keywords, new link building campaigns. Nothing moved.
Then we ran the crawl.
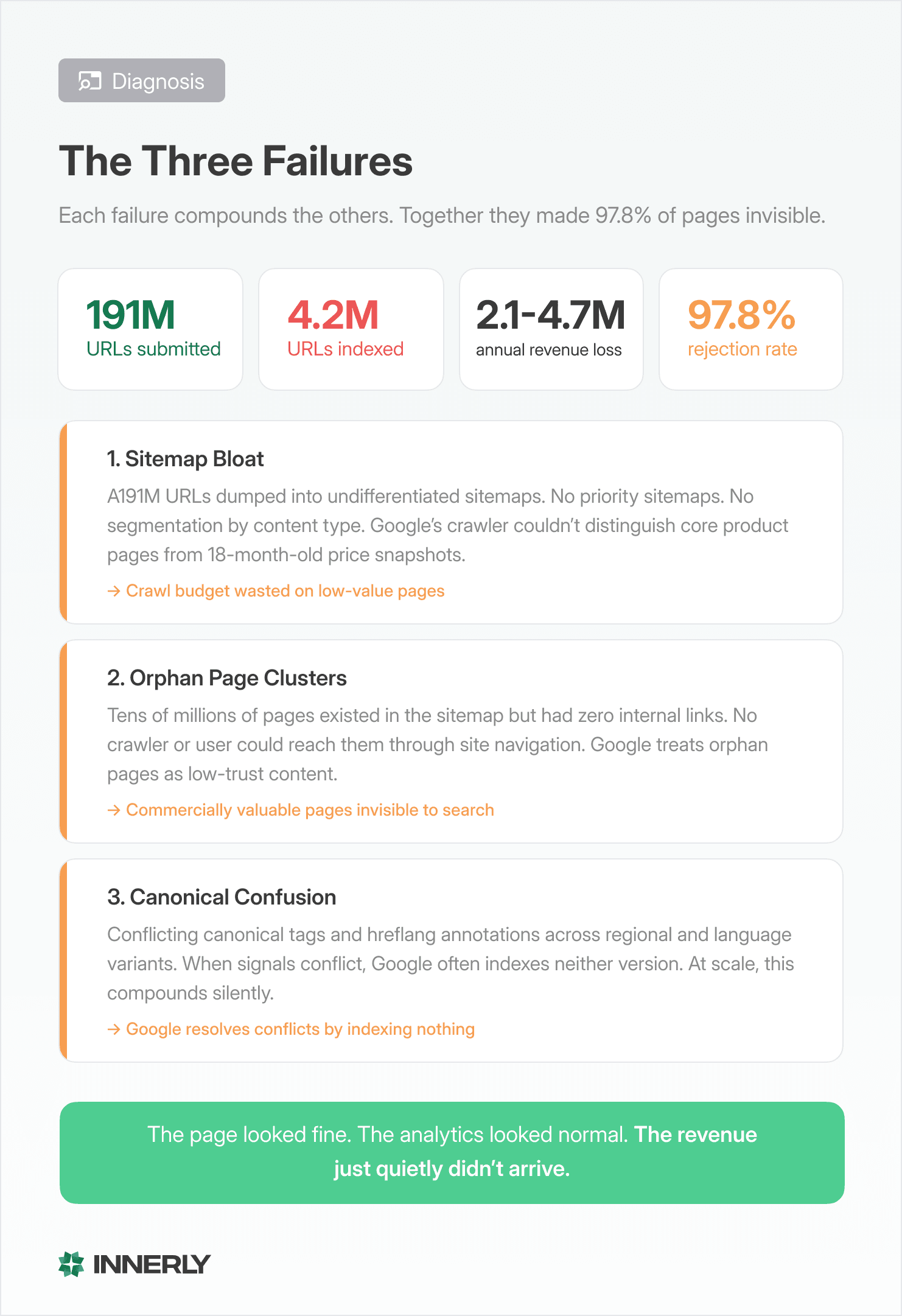
The exchange had submitted 191 million URLs to Google through their sitemaps. Google had indexed 4.2 million of them. That’s a 97.8% rejection rate. For every 100 pages the exchange asked Google to index, Google said yes to two.
The CMO’s first reaction: “That can’t be right.”
It was.
And the revenue impact was not theoretical. Every unindexed page that targeted a commercial keyword (a trading pair page, a market data page, a localized landing page) represented organic traffic that could never arrive. Users searching for those terms would find competitors instead. Not because the exchange’s content was worse. Because Google didn’t know it existed.
This is the indexation crisis. It’s happening at every large crypto exchange. And almost nobody is watching for it.
Why Large Exchanges Are Structurally Vulnerable
To understand why 97.8% of pages were invisible, you need to understand how crypto exchanges generate content at scale.
A major exchange doesn’t have a content team writing 191 million pages. The pages are generated dynamically. Every trading pair gets a page. Every market data snapshot gets a page. Every combination of asset, language, and region creates another URL. Multiply 800 trading pairs by 15 languages by 12 regional variants, and you’re already at 144,000 pages before you’ve written a single blog post or help article.
Now add historical price data pages. Add token profile pages for every listed asset. Add academy content localized across markets. Add futures and options variations. Add copy trading profiles. The URL count expands geometrically.
Most of these pages are legitimate. They serve real user intent. Someone searching for “ETH/USDT price” or “Bitcoin trading pair Bitc…” in Portuguese should find a useful, accurate page on your exchange. Each one is a potential entry point for a new user.
But Google has a finite crawl budget for every domain. Even for a top-10 exchange, Google won’t crawl 191 million URLs. It has to choose. And when your sitemap offers no clear signals about which pages matter most, Google’s crawler does what any system does when overwhelmed: it defaults to what it already knows and ignores the rest.
The result is a domain where the homepage, the blog, and a handful of high authority pages get crawled and indexed normally. Everything else enters a queue that functionally never gets processed.
The Three Failures We Found
Every large site indexation crisis is unique in its details but follows predictable patterns. In this exchange’s case, three interconnected failures were responsible for the 97.8% rejection rate.
Sitemap bloat without prioritization. The exchange submitted every dynamically generated URL in its sitemaps. All 191 million of them. No priority signals. No segmentation. No distinction between a core product page and a historical price data snapshot from 18 months ago.
Google’s documentation is clear on this: sitemaps with more than 50,000 URLs should be split into multiple sitemap files, and those files should reflect the site’s actual architecture. When an exchange dumps 191 million URLs into an undifferentiated sitemap, it’s the equivalent of walking into a library and asking the librarian to catalog every scrap of paper in the building, including the receipts in the trash cans.
The fix isn’t submitting fewer URLs. It’s submitting them intelligently. Segment sitemaps by content type: core product pages, trading pair pages, educational content, localized variants. Set priority and lastmod signals that reflect actual business value. Give Google a map, not a data dump.
Orphan page clusters. The second failure was structural. Tens of millions of pages existed in the sitemap but had no internal links pointing to them from anywhere else on the site. They were technically accessible via URL, but no user or crawler would ever find them by navigating the site.
Google calls these “orphan pages.” They’re pages that exist in isolation, disconnected from the site’s link architecture. For a search engine, an orphan page is a trust problem: if the site itself doesn’t link to this content, why should Google invest crawl resources to index it?
In this exchange’s case, the orphan pages were primarily localized market data pages and historical trading pair snapshots. The dynamic generation system created them, the sitemap listed them, but the site’s navigation, internal linking, and content architecture treated them as if they didn’t exist.
The revenue implication is direct. Many of these orphan pages targeted long tail commercial queries in specific markets. A user searching for a niche trading pair in Turkish or Portuguese would find zero results from this exchange, despite the fact that the exchange had a dedicated page for exactly that query. The page existed. It was orphaned. It was invisible.
Canonical confusion at scale. The third failure was the most technically subtle and the most damaging.
When a site generates multiple versions of similar content (different language versions, regional variants, parameter based URLs), it needs to tell Google which version is the “canonical” or primary version. This is done through canonical tags, hreflang tags, and URL parameter handling.
This exchange had conflicting signals everywhere. Pages with self-referencing canonicals that contradicted their hreflang annotations. URL parameters that created duplicate content without canonical resolution. Regional variants that pointed their canonical tags to a language version that no longer existed.
For Google’s systems, conflicting canonical signals are a stop sign. When the crawler encounters a page that says “I’m the canonical version” but another page disagrees, it often chooses to index neither. At scale, across millions of pages with inconsistent canonical implementation, this single technical issue was responsible for a significant portion of the unindexed pages.
Translating Technical Problems into Revenue
Here’s where most technical SEO audits fail their audience. They find the problems. They document the problems. Then they hand the CMO a spreadsheet full of HTTP status codes and expect action.
That’s not how decisions get made.
When we presented findings to the exchange’s leadership team, we didn’t lead with crawl budget or canonical tags. We led with revenue.
The calculation is straightforward. Take the number of unindexed pages that target commercial keywords. Estimate the search volume for those keywords across all target markets. Apply a conservative click through rate based on the exchange’s typical ranking positions. Multiply by the exchange’s average conversion rate from organic search visitor to registered user. Multiply by the average revenue per user.
The numbers were significant. We estimated the indexation failure was costing the exchange between $2.1 million and $4.7 million in annual organic revenue. Not because the content was bad. Not because competitors had better products. Because Google didn’t know the pages existed.
That’s the number that moved the conversation from “interesting technical finding” to “executive priority.”
The range reflects uncertainty in the estimation: the lower bound assumes conservative click through rates and conversion, while the upper bound assumes the exchange would capture market average performance across all target markets. Even the conservative estimate justified an immediate remediation program.
The Remediation Playbook
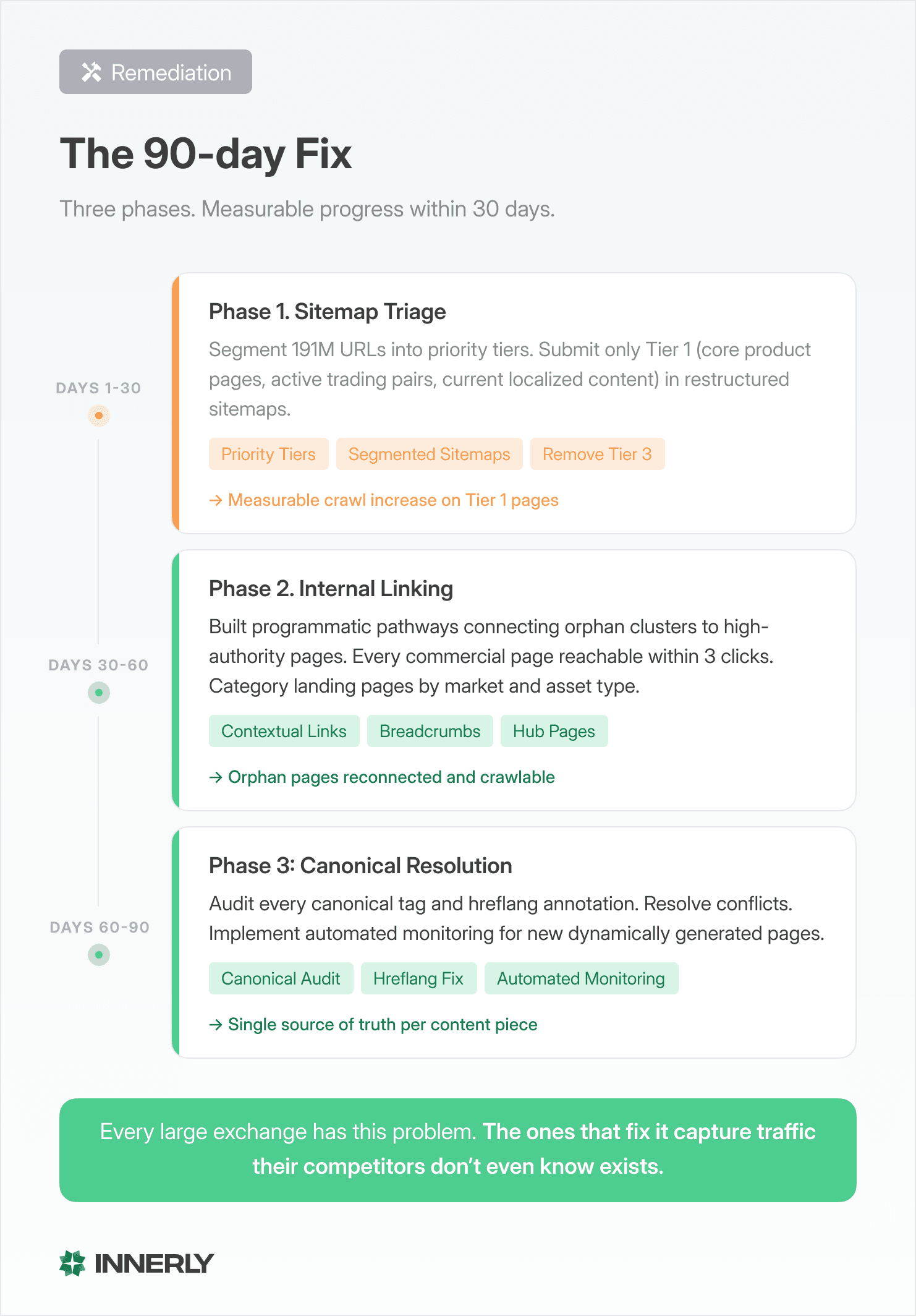
We approached the fix in three phases, designed to show measurable progress within the first 30 days while building toward a complete architectural solution.
Phase 1 (Days 1 to 30): Sitemap triage. Segment the 191 million URLs into priority tiers. Tier 1: core product pages, active trading pairs, and current localized content. Tier 2: secondary market data and educational content. Tier 3: historical snapshots and low value dynamic pages. Submit only Tier 1 in restructured, segmented sitemaps. Remove Tier 3 from sitemaps entirely (not from the site, just from the sitemap submission).
Result within 30 days: Google’s crawl activity on Tier 1 pages increased measurably. The crawler was no longer spending budget on 18 month old price snapshots. It was focusing on the pages that drive signups.
Phase 2 (Days 30 to 60): Internal linking architecture. Build programmatic internal linking pathways that connect orphan page clusters to the main site architecture. This means adding contextual links from hub pages to their associated trading pair pages. Adding navigation breadcrumbs that reflect the actual content hierarchy. Creating category landing pages that organize localized content by market and asset type.
The goal isn’t to link every page to every other page. It’s to ensure that every commercially important page is reachable within three clicks from a high authority page. Google’s crawler follows links. If the links don’t exist, the crawler never arrives.
Phase 3 (Days 60 to 90): Canonical and hreflang resolution. Audit every canonical tag and hreflang annotation across the active page set. Resolve conflicts. Establish a single source of truth for each piece of content and its regional/language variants. Implement automated monitoring that catches canonical conflicts when new content is dynamically generated, before they compound.
This is the longest phase because canonical issues at scale require coordination between the SEO team, the engineering team, and the localization team. Each group touches the system at a different point, and each can introduce conflicts without realizing it.
Why This Matters Beyond One Exchange
We’ve audited multiple exchanges since this engagement. The patterns repeat.
Every large crypto exchange generates content dynamically at scale. Every one struggles with sitemap management. Every one has orphan page clusters. Most have canonical conflicts they don’t know about. The specific numbers vary (some have 50 million URLs, some have 300 million), but the structural vulnerability is universal.
And the competitive implications are real. An exchange that fixes its indexation captures organic traffic from keywords its competitors haven’t even targeted. Not through better content or bigger budgets, but through basic technical hygiene that makes existing content visible.
The CMO who called us wasn’t dealing with a content problem or a keyword problem. The exchange had the content. It had the pages. It had the keywords. What it didn’t have was visibility, because a technical failure was silently preventing Google from seeing what the exchange had already built.
That’s what makes indexation crises so dangerous. They don’t show up in your content dashboard. They don’t trigger alerts. They don’t cause pages to 404 or throw errors. The pages look fine. The analytics look normal (because they only measure what Google can see). The revenue just quietly doesn’t arrive.
If you’re running organic for an exchange with more than a million dynamically generated pages, this is worth investigating. Not next quarter. Now.


